


Centralized v.s. Distributed
A practical guide for an Engineering organization

Should something be done centrally by “experts”, or should the people closest to the action have the power to decide for themselves?
This is a universal debate that happens everywhere, all the time, and will likely never stop. Federal v.s. State regulation, government enterprise v.s. free market, school provided lunch v.s. self packed lunch, git v.s. svn, monolith v.s. microservices, and many many more are all manifestations of the same debate. Even decisions as small as whether to refactor duplicate code into the same function, is very much a Centralized v.s. Distributed problem.
Most people can agree that there isn’t a universal way to settle the debate, so ironically, the solution to the Centralized v.s. Distributed problem will have to take a distributed form.
There are however, heuristics to follow, for example explore-then-exploit, or let 1000 flowers bloom, as well as factors to consider, when picking a side for a specific situation. Having a good understanding of these factors for the given problem can increase the likelihood of making a better decision.
Some relatively non-controversial factors to consider are summarized below.
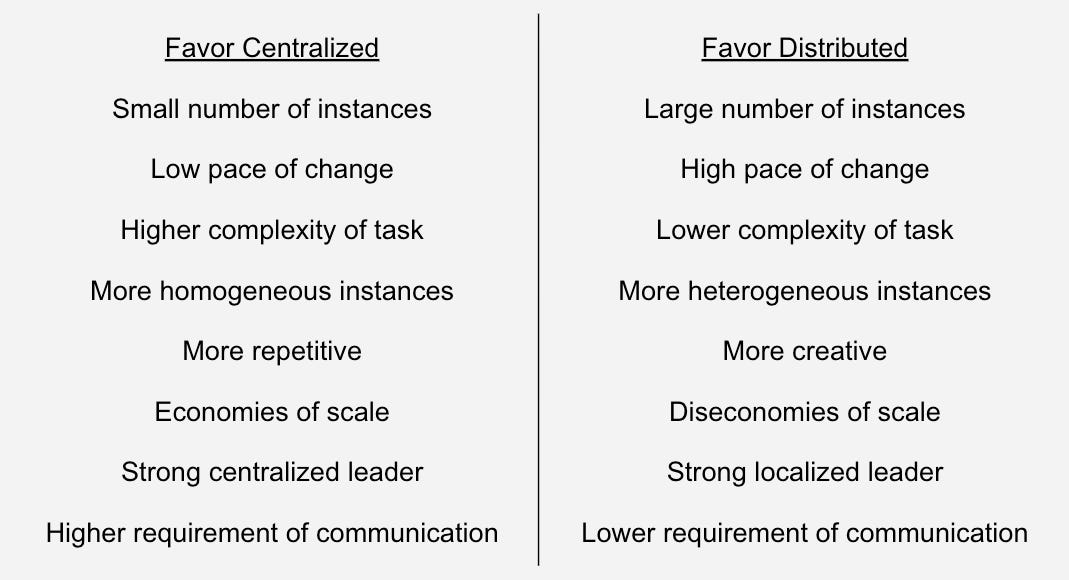
When it comes to managing an engineering org and its work, there are specific decisions that need to be made about whether, and to what degree, each item should be centralized or distributed. Here are my opinions.

Strictly Centralized
Programming Language
For most companies, picking 1-2 languages per platform seems sufficient. Given the rather large amount of work and expertise required for maintaining a language stack, the long term implications of introducing another language, I believe very few people should have the power to make this decision, and they should take it rather carefully.
Cloud Platform
Similar to a programming language, cloud platforms nowadays not only provide great convenience in deploying software, it also affects how systems are built and communicated with each other. With a tremendous amount of expertise required and very large switching cost, this should again be an uncontroversial, centralized item.
Security Standards
In the current day and age where a data breach could realistically kill a company, it is, again, likely too much to ask individual teams of generalist software engineers to look after their own security exposure, especially if the teams are small.
Centralize the baseline, allow for small deviations
Deployment Pipeline
On a per platform basis (e.g. frontend, backend, mobile app), most of a company’s software is likely deployed in a very similar way. As a result, there’s significant leverage to be gained by building shared infrastructure to make the common path as trivial as possible.
On the other hand, there is a meaningful variance between teams that have reasons to iterate at different paces, which should be reflected in their deployment tooling. Machine Learning teams building models, or teams subject to stricter requirements such as PCI or HIPAA are classic examples requiring tweaked deployment models.
Project Management
Most product engineering teams can likely get their jobs done roughly equally well regardless of where their tasks reside. Take any of jira or Shortcut or Monday.com, it’d probably work. Occasionally, you come across one team that loves Notion so much that they copy everything into Notion anyway. Is it worthwhile forcing them out of their favorite tool? I’d say let them try and see how it goes.
Cloud Resources
Once all the teams are on the same cloud provider, I think we can give teams a little more freedom to explore which offering suits their needs the best. There’s obvious efficiency gains, and cost control benefits in having a standard process of provisioning commonly used resources (e.g. AWS S3 bucket). But on the other hand, should a team wait weeks for approval if they’d like to try out AWS Kendra (I didn’t know what it is 5 minutes earlier either) for a quick prototype? I would say no.
Hiring and Personnel Management
This one seems to have a fairly large variation, ranging from Google’s completely team blind hiring process, to the possibility of each team devising their completely independent hiring process.
Having done this for a couple of years and tried a few different options, I’m of the opinion that there should be a common baseline process and standard held across the teams, including well defined engineering levels. On top of it, if certain teams have specific requirements about their role, technically or culturally, I think the hiring manager can make the appropriate adjustments, given they have the most skin in the game on hiring decisions.
Centralize the tooling, distribute the usage
Operational Responsibilities
It seems to be widely accepted now that completely separate Development and Operations teams that don’t have much context about what each other is doing, doesn’t work very well. As a result, the team that wrote the code is typically also taking on the operational responsibilities of their system, including monitoring, being on-call, and incident management. To me, that’s a good thing.
Of course, if every team has a different way of getting logs from their system, a different monitoring solution to look at metrics, and a different way to deploy a roll-back, maybe that’s too much.
Code Repository
As long as the code is on Github, or Gitlab, or whichever hosting solution we pick, leave the teams to configure their own repos to their likings. If a team prefers merging to rebasing, what harm does it have if they only do it in the repository they own?
Testing Infrastructure
Similar to the Operations team, the QA team also seems to be on a decline, and in my opinion, for a good reason. The main argument I heard against having a QA team is that it spoils the development team into the bad habit of not thoroughly testing their code. While somewhat valid, this is actually not my biggest reason for objection.
Personally, I believe that to write good tests, at whichever level of abstraction, requires a significant amount of work to deeply understand the product and the system. Having spent the time and effort to train a group of people to be such experts of the product and system, but not have them contribute actual production code, seems to be a great form of waste.
As a result, writing tests should be squarely the responsibilities of the individual teams.
Boilerplate Utilities
There are a number of commonly used utility toolings that are fairly typical to be shared among engineering teams. From internal libraries for authentication, to distributed tracing tools such as Jaeger, to error reporting tools such as Sentry, these are common utilities that can be rather effectively templatized. Ask the teams to use the template for an efficient set-up, then set them loose.
Distributed, within reason
In my opinion, almost everything else can be distributed to the individual teams to make their own best decisions, within reason. Ultimately, there are technological as well as business constraints that teams have to respect.
This category includes but is not limited to:
Development process, including framework, rituals, iteration cycles etc
System performance metrics, SLOs, SLAs
Sub-team organization and personnel
Almost everything within the code repository, including coding style, build tool, etc
Software frameworks (e.g. fast-api), communication interfaces (e.g. grpc)
Conclusion
Coming from a fast-paced start-up background, my default is always to allow for distributed decision making until it proves too much. There are a few reasons for this.
First, the distributed model optimizes for pace and learning. When something is done locally, it tends to get done faster, and can iterate more frequently. The ability to trial and error quickly is the one main advantage smaller companies have against the more established competition. This is exactly the Innovator’s Dilemma.
Second, distributed decisions do not automatically lead to inconsistency. When something is tried on a smaller scale and finds success, it can spread rather quickly. A grassroots solution can easily trump a centrally designed solution forced down to the teams’ throat.
However, as the size of the company and engineering team grows, there will be a need to centralize more items, as consistency and efficiency gains more leverage, and as higher level engineers chase more impact, which at some point, can only be achieved via doing centralized work.