


Is the Dependency Inversion principle a fad?

The “D” in the SOLID principles stands for “Dependency Inversion”, stating that classes should "depend upon abstractions, not concretions".
In specific terms, one of the common manifestations of this principle is to have the business logic code depend on a data access “interface”, which may have different concrete implementations that the business logic code does not need to care about. This is also a key insight of Clean Architecture, inlining an illustration from the said post here.
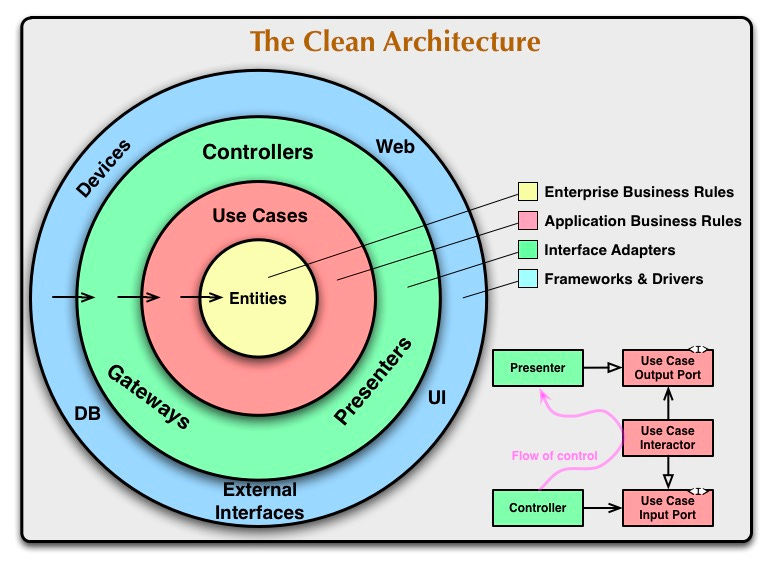
However, anyone who worked on large systems may feel some unease about this principle, because even if we’re not sure exactly why, we have a hunch that ultimately, implementation details do matter, and not just because of Hyrum’s Law.
Latency
Latency is arguably the most obvious aspect of a function’s behavior that is not captured in its interface.
If your code relies on user_repository.get_all_users() it does not tell you how long it might this function call to return, because the theory says, it’s “a concretion” not an “abstraction”, hence not something you should depend on.
Worse, different implementations of the method may even take wildly different durations of time to return. in_memory_user_repository.get_all_users() could take a few milliseconds, whilst data_warehouse_user_repository.get_all_users() may take 30 seconds. It’s difficult to argue that the consumer of this interface must be agnostic to this, and other meaningful, yet hidden differences, in behavior.
Yes, there are techniques such as timeouts, circuit breaking, and deadlines you can use to make the system work more robust. But that’s exactly the point, that latency, and performance in general, matters.
Resource Consumption
Have you ever gotten your process/container/application killed due to Out-of-Memory? Well, wouldn’t it be nice if functions can natively be constrained to not use more than a certain amount of memory, as part of its defined interface?
And of course, memory is not the only precious resource, other factors such as external network calls, data transfer volume, disk space usage, are all factors that the consumer of an interface may want to put constraints on to align with its downstream processing.
If your code runs on a platform (e.g. Salesforce) that has hard limits, or expensive quotas, you may even want to tightly control the distribution of the quota to the internal functions, just so you don’t accidentally get a $1 million bill because one of the engineers forgot to batch up a query to the database in their quick hotfix.
Failures
And of course, running out of resources is not the only form of failure. As a consumer of an interface, you may also care about other ways a function may fail.
To this end, Java has the concept of Checked Exceptions as part of function signatures, that forces its consumer to deal with it. Even though this might be a controversial subject, the objection seems to be more about the way it's enforced in the compiler than the concept itself.
Overall, I do think the direction of supporting functions to natively document its failure modes, for example in the form of exceptions, is sound.
What now?
Dependency inversion is a very useful pattern, however given how much more sophisticated software has evolved to be, function interface definitions that haven't changed much for 50 years are starting to look insufficient.
If we maintain that the consumer of an API should truly only care about its abstraction and not concretions, the only way out is to expand what counts as an abstraction.
To that end, if you're using Python, you're in luck. liang is an open source python package that allows you to annotate exactly how long any function can take, how to measure it, and what to do with it if it takes too long.
To build more robust software, we've got to stop pretending we don't care about "implementation details".